What Are Classonomies – and why you may want to avoid them
Classonomy is a word I heard recently from a colleague. It is not real word, but a made up term that resonated with me because it describes well a specific type of ontologies I come across frequently – especially, but not limited to, in the Life Sciences domain.
Classonomies consist of classes. Typically, a very large number of classes. The classes, while otherwise largely “undefined”, may be organized taxonomically using rdfs:subClassOf statements. By undefined, I mean classes that have no ontological definitions. Classes that do not define characteristics (i.e., properties) of their members. Instead, they have the kind of information one typically associates with instances e.g., synonyms, acronyms, various identifiers, descriptive text and, possibly, variety of other statements. Some classonomies are flat with no subclass relationships.
I am motivated to write this blog because a number of our customers are impacted by the challenges of having to work with the classonomies such as the ones they download from the BioPortal. A confusion happens over what is an ontology, how an ontology should look like, what it should contain and how to use it.
Example of a Classonomy
To better illustrate what I mean by a classonomy, let’s take a look at one example from the BioPortal.
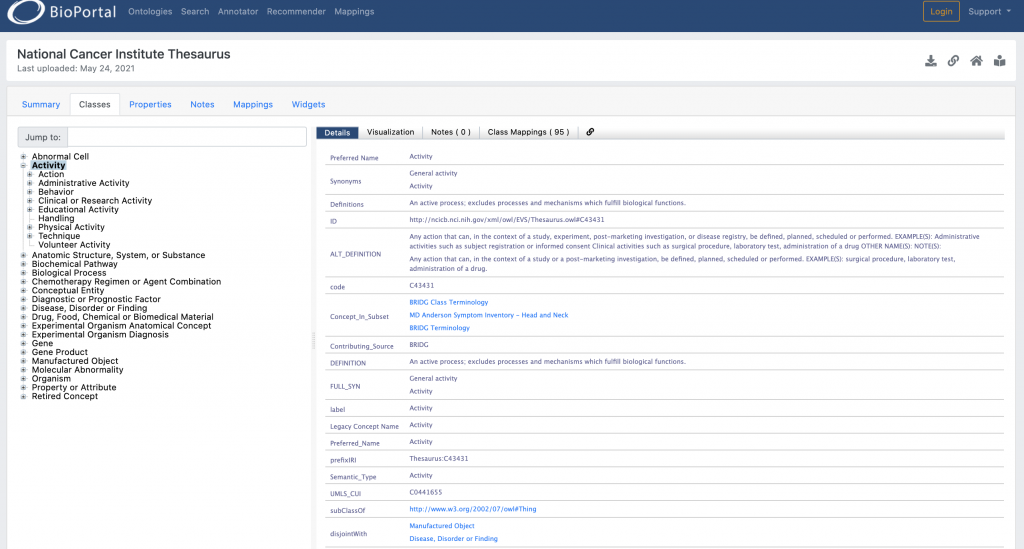
We see a large number of terms with some hierarchical connections between them to identify broader and narrower terms. For each term, we see some synonyms and definitions. In case of Activity, the definitions are:
“An active process; excludes processes and mechanisms which fulfill biological functions.
Any action that can, in the context of a study, experiment, post-marketing investigation, or disease registry, be defined, planned, scheduled or performed.
EXAMPLE(S): Administrative activities such as subject registration or informed consent Clinical activities such as surgical procedure, laboratory test, administration of a drug.”
We also see information of lexical nature such as preferred name, legacy name, etc. There are also identifiers (code, UMLS_CUI). We, as people, reading this information can get a good sense of the meaning of the term “activity”. What we DO NOT see is any semantic definition that a machine could use for working with activities i.e., processing them. That is unless the processing is purely lexical – parsing of text, tagging of documents, etc.
Let’s take a look at another term – Diagnostic, Therapeutic, or Research Equipment under the Manufactured Object.
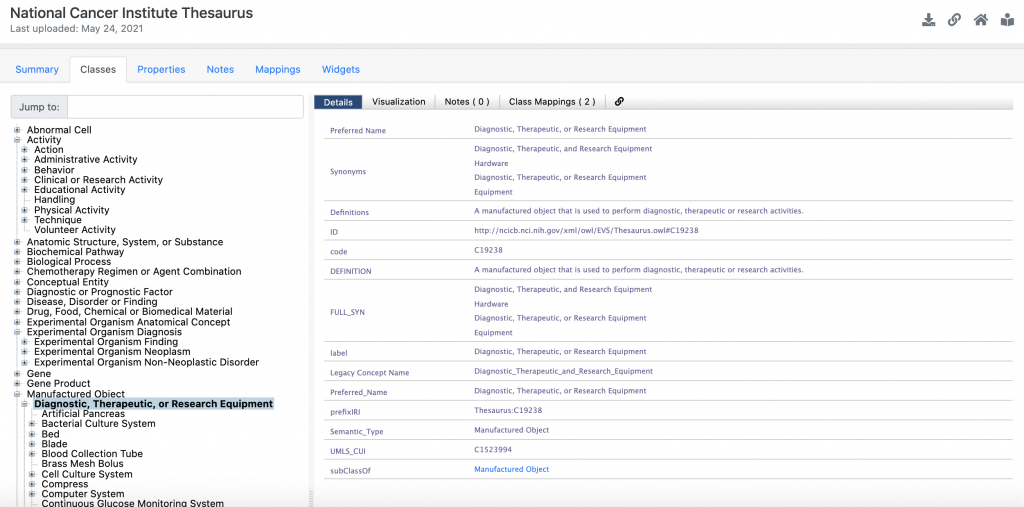
Again, we see some synonyms and identifiers and we see a definition.
“A manufactured object that is used to perform diagnostic, therapeutic or research activities.”
From the definition we, by reading the text, clearly understand that there is a relationship between the diagnostic, therapeutic and research activities and this type of equipment. We also understand the nature of the relationship. This understanding, however, is not conveyed in a way that could be easily understood by computers. In other words, we are not looking at an ontology, we are looking at a lexicon or a lexical dictionary. Here is the definition of lexicon from Wikipedia:
A lexicon is the vocabulary of a language or branch of knowledge (such as nautical or medical). Linguistic theories generally regard human languages as consisting of two parts: a lexicon, essentially a catalogue of a language’s words (its wordstock); and a grammar, a system of rules which allow for the combination of those words into meaningful sentences. In some analyses, compound words and certain classes of idiomatic expressions, collocations and other phrases are also considered to be part of the lexicon. Dictionaries represent attempts at listing the lexicon of a given language.
In fact, the name of this “ontology” speaks for itself. It is the “National Cancer Institute Thesaurus”. Thesauri are not ontologies. This particular thesaurus is further described as “a controlled vocabulary in support of NCI administrative and scientific activities”.
How an Ontology May Look Like
First, let’s be specific as to what the term ontology refers to in the context of this blog. There are many different definitions of ontology. Originally, the world was used only to refer to a branch of philosophy. The term ontology and the corresponding field of philosophical study existed long before computers.
Our interest, however, is in ontologies as they apply to computer science. Because of this, we will not talk about the ontological theories of Aristotle, Descartes or Heidegger. Instead, we will focus on ontologies that are used by computers. Wikipedia’s definition of ontology in computer science is:
In computer science and information science, an ontology encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities that substantiate one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of concepts and categories that represent the subject.
Classonomies contain few, if any, definitions of this kind. In case of the NCI Thesaurus, there are a few such definitions. They are mostly limited to the “top level” classes such as Activity. We will use these definition to demonstrate how an ontology should look like. I have imported the NCI Thesaurus into an ontology in TopBraid EDG to demonstrate class definitions. I have done this because we can not easily see this information in the BioPortal.
The screenshot below includes a class diagram showing that activities can have a target anatomy and target diseases and can use manufactured objects.
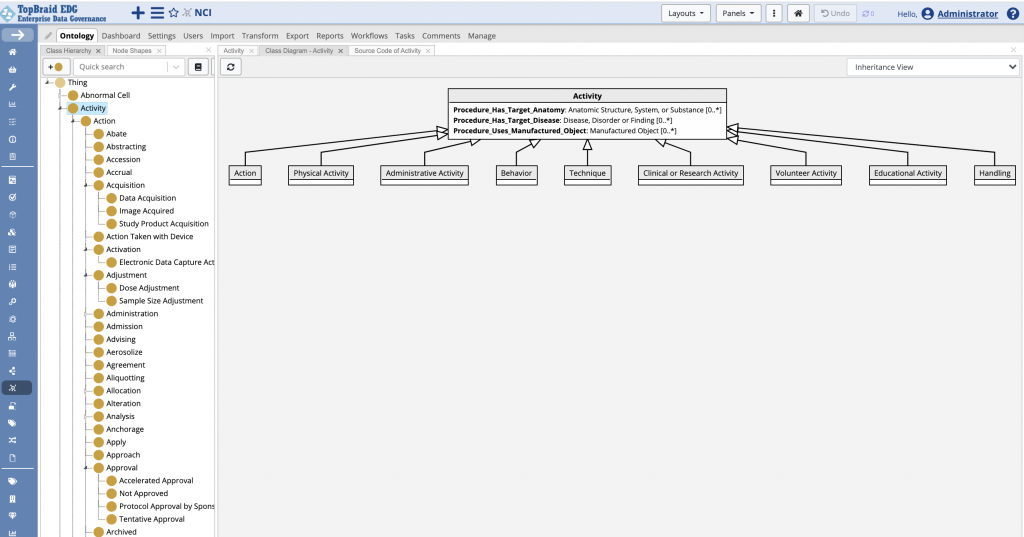
This means that the software using the NCI Thesaurus as an ontology would, for example, know that it is legitimate to ask what disease is targeted by an activity or what manufactured object (e.g., instrument) is used to perform it. Note that, typically, activities in ontology models are defined as having a duration (start and end) and by having a performing party (a person, group of people, or technology in case of fully automated activities) that is responsible for performing it. However, the NCI Thesaurus does not find these to be important factors in defining the meaning of activity.
The ontological definitions in the NCI Thesaurus are very sparse compared to the number of classes. They are available for only a very small subset of classes. Not even all the top level classes have them. For example, the top level class Abnormal Cell does not. Classes below the top level rarely have such definitions. We see from the image above that none of the subclasses of the Activity do. Since the NCI Thesaurus primarily uses rdfs:domain to say what properties may be applicable for class members, the statements it makes about a class do not mean anything for subclasses.
For example, using rdfs:domain to say that an Activity can be performed using a Manufactured Object does not mean that a Diagnostic, Therapeutic and Research Activity can be performed using a Manufactured Object. Semantics of RDFS is such that statements about classes do not say anything about subclasses. It is always the other way around – RDFS statements about subclasses say something about parent classes.
The image below shows one of the exceptions where the Cellular Process, a subclass of the top level class Biological Process, has some definition.
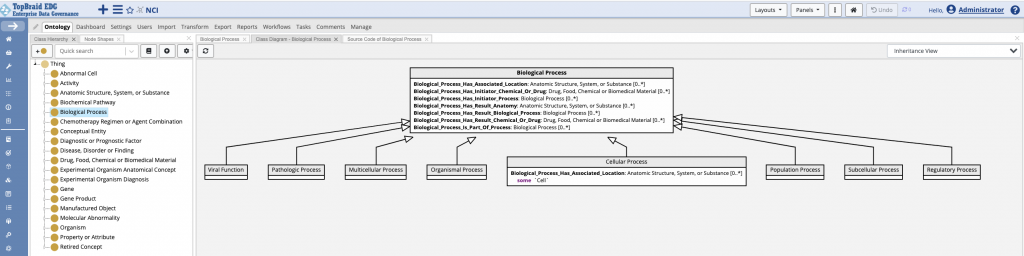
There is an OWL restriction that makes a specific statement about a location of a Cellular Process. This statement applies to all subclasses of the Cellular Process.
Now that we looked at what kind of information is expected in an ontology, we can talk about why one should avoid classonomies.
Why Not To Use a Classonomy
There are a number of reasons why creating ontologies of a classonomy type is not a good idea and why their use is problematic. Below are some key ones.
It is quite common for classonomies to not mean what they say they mean. NCI Thesaurus uses rdfs:subClassOf relationship between classes. The meaning (semantics) of this relationship is defined very clearly by the RDFS standard.
If class A is a sub class of class B, then any instance of A is also an instance of B.
This is the entire meaning of the subclass relationship. If this is not what you mean, you should not be using this relationship. The NCI Thesaurus uses this relationship throughout, but when you examine its content, it is clearly does not mean it – or rather sometimes it does mean it and sometimes it does not.
If we expand the class Activity, we see Research Activity.
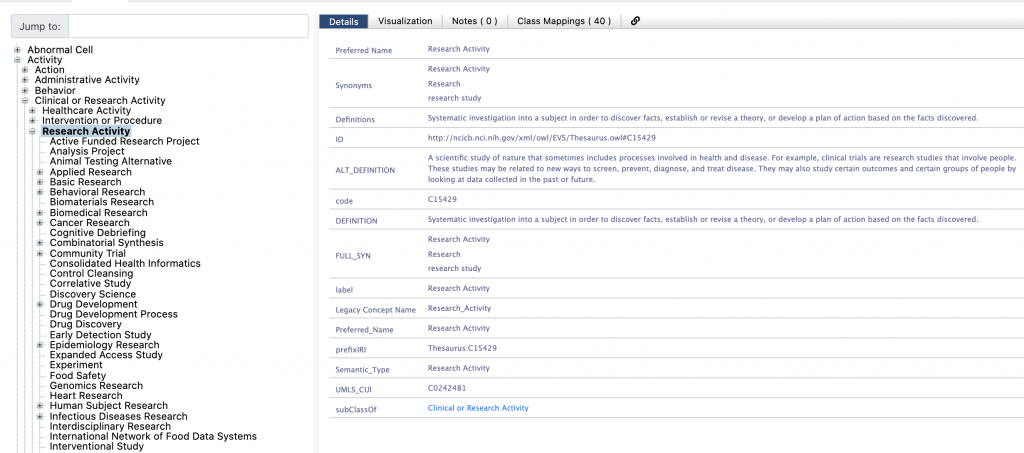
So far, so good, a research activity is an activity. Note that one of the class properties is “semantic type”. It is simply a string, but if we look up the description of this property, it says:
“A property that represents a description of the sort of thing or category to which a concept belongs in the context of the UMLS semantic network.”
The description make it sound as if the values of this property should actually be classes that a given NCI term belongs to. Classes are categories or sets of instances. The semantic type of Activity is “Activity” and the semantic type of Research Activity is “Research Activity”. We could wonder why it is simply a string and what it means for Activity to have a semantic type “Activity”, but let’s leave this question aside and simply use this information to better understand the type or category of each term.
Many subclasses of Clinical or Research Activity make sense as subclasses according to the RDFS semantics – they do represent clinical or research activities – like Cancer Research or Behavioral Research. And by and large, their semantic type indicates an activity. Many, but not all. Look, for example, at the Food Safety class.
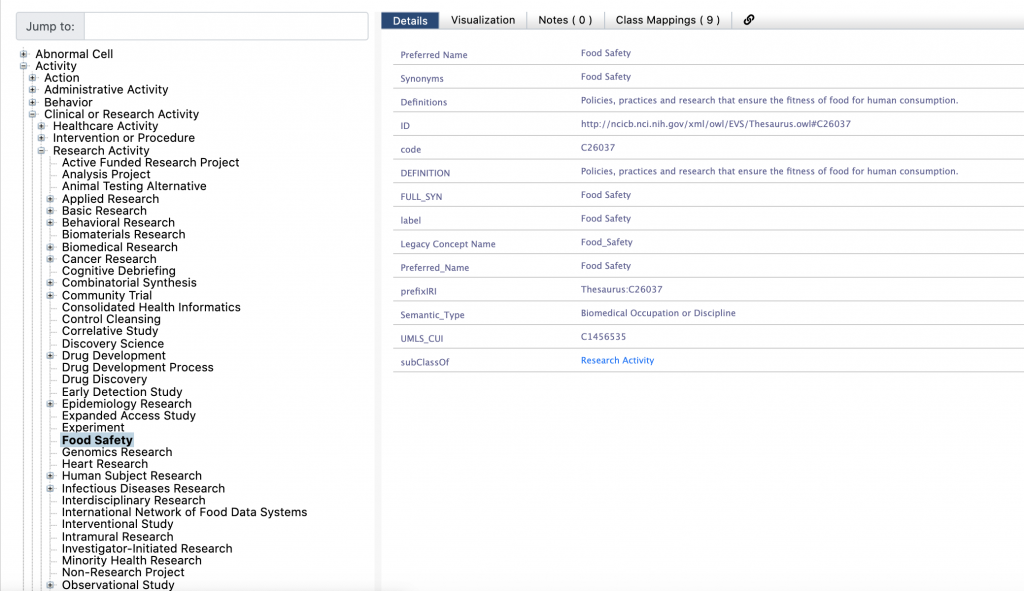
Its definition does not quite fit a concept of an activity:
“Policies, practices and research that ensure the fitness of food for human consumption.”
Food safety research is a research activity thus, an activity. But what about food safety policy? Not so much. The class, however, is meant to be a set of all these things – policies, practices as well as research. Also note that Food Safety’s semantic type is “Biomedical Occupation or Discipline”. This does not sound like an activity either.
Similarly, under the Clinical Observation class, we can find classes like First Year Reported. It has the following definition.
“The year that something was first noted.”
Does this mean that the year 2021 would be a member of this class? If we are to believe the name and the definition, then the answer would be yes. This would mean that the year 2021 is a Clinical Observation and, in turn, a Healthcare Activity – which does not make sense. We can only interpret the meaning of this class based on the verbal description since there is no semantic definition,
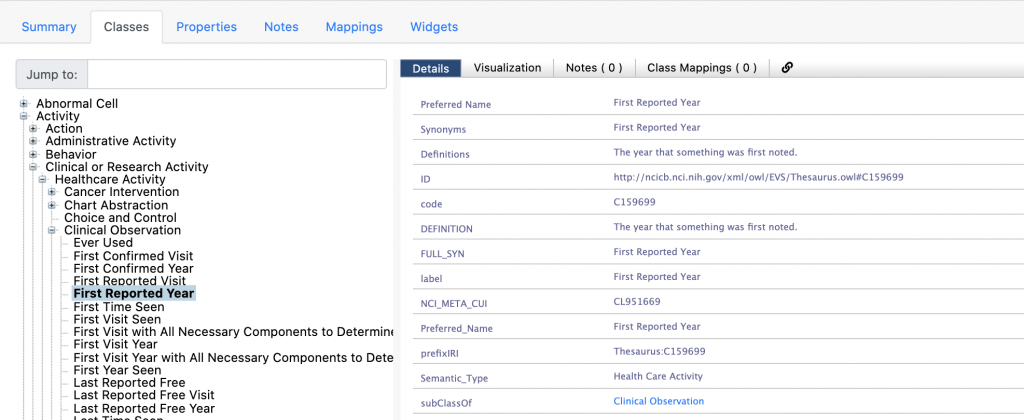
Thesauri are not expected to be semantically precise. They simply group broader and narrower topics. And this is what we see in this thesaurus. Some classes in this hierarchy are described so that they could, indeed, be subclasses of the parent – their instances would pass the logical test of being instances of the parent classes. Names and descriptions of others indicate that they could contain instances related to the instances of the parent class, but not instances that are members of the parent classes.
This happens when you think of classes as simply vocabulary terms and not as classes – which brings us to the next point.
Misuse of Classes
Classonomies not only lack class definition, but also commonly define as classes resources that can’t be classes because they are not sets of individual resources.
Rule #1 of the Ontology Development: If you can’t answer a question about what resources will be members of a class, you can’t create a class. A class IS a set of resources. It is not just a term.
Let’s imagine that we have an Airspace classonomy where we created a class Apollo-13 and made it a subclass of class NASA and NASA a subclass of Space Agency. If we think about these as terms only, could we say that Apollo-13 is somehow “under” NASA? Yes, most certainly. In a book or a website index, Apollo-13 could be under NASA as a topic.
However, these things do not have a subclassOf relationship. Nor are they classes. They are related because Apollo-13 is a mission conducted by NASA which is a space agency. NASA could be a member of the class Space Agency. Apollo-13 could be a member of the class Space Mission, but not a member of the set of things that are classes – unless one can identify different missions or different vehicles that could all be members of the Apollo-13 class. And even if one could identify such things, it is hard to imagine how they could be also members of the class Space Agency.
We see similar examples in the NCI Thesaurus and in other classonomies available in the BioPortal. The NCI Thesaurus assigns identity to any term that may be used in the context of the NCI’s activities. As you can imagine, relevant lexicon consists of more than 100 thousand terms. Each is declared to be a class – whether it could ever make sense as a class or not. For example, in the NCI Thesaurus countries are declared to be classes.
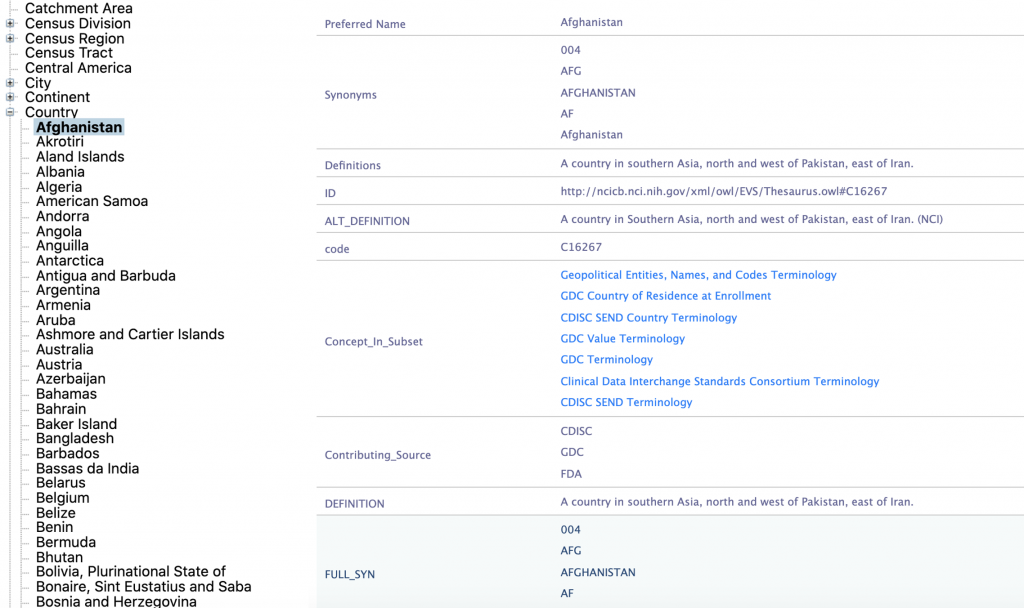
Cities in the NICI Thesaurus are also declared to be classes. Specific programs and/or tools are declared to be classes e.g., the Foundation Stock Service.
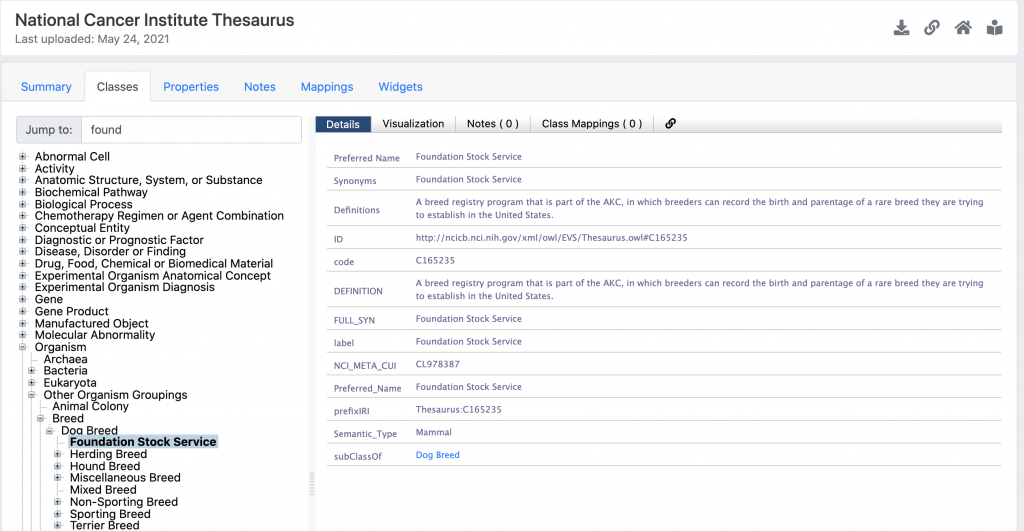
These “classes” could be grouped under items they clearly do not have a subclass or even “type of” relationship to – like the Foundation Stock Service and the Dog Breed -> Bread -> Organism.
Ontologies are expected to be semantically precise. When we create an ontology, we must always think what are the instances of each class we create. If you can’t answer this question, don’t create a class. As discussed in the previous point, when we connect classes using rdfs:subClassOf relationship, we are saying that any instance of a child class is always an instance of the ancestor classes. Both of these required practices are frequently ignored by creators of classonomies.
Lack of Clarity of the Scope and Intended Use
Classonomies, as above examples show, contain a conflation of things. When you use them, you can never count on a class being a class. Or on consistent treatment of the ontological definitions – if such exist.
Classonomies are often very large, making it difficult to integrate them with other information you may want to use. They are most suitable as lexicons or dictionaries, but they often contain too much information you do not need and too little information that you do need. By too much, I mean that with tens or even hundreds thousands classes, they contain a lot of terms – many of which may not be of interest to you at all or many not be of interest to some of the specific applications where you want to use them. However, as explained below, they are “all or nothing” proposition. By too little I mean that they may not be sufficiently reach in their treatment of synonyms and other lexical information for the terms you are interested in.
Classonomies can also be problematic for tools. Tools that work with ontologies make certain assumptions about what information they expect to see about classes, properties and instances. Classonomies being something in between are likely not to meet some of these assumptions and will require custom treatment.
How to Recognize a Classonomy
Recognizing a classonomy is easy. Here are the most common signs indicating that you are dealing with a classonomy:
- You see thousands of classes
A typical ontology will be of a relatively modest size. An ontology with hundreds of classes is considered large. An ontology with a thousand classes is very large. It is hard to define a useful model of a very large size. You need to think about the context of its use, about the degree of the ontological commitment you are ready to make, etc.
If you see tens or hundreds of thousands of classes, you are most likely looking at a classonomy. It is much easier to simply get the commonly used terms, organize them into a taxonomy and give each a verbal definitions – these are typically already readily available in books and in the web or print dictionaries.
- You see classes that are clearly not classes
Like Afghanistan under countries or Pfizer under companies.
- Classes (and properties) are described using custom properties
Custom properties are those that are not provided by the standard ontology modeling languages RDFS/OWL and SHACL. And there are no definitions of what they mean and how they are to be used in the models.
This includes the use of SKOS properties with classes as well as the use of custom annotation properties. Typically, classes (and properties, property shapes, OWL restrictions) in an ontology are described using language constructs that are standard in RDFS/OWL and/or SHACL. This ensures interoperability across tools because they understand definitions of the ontology statements. The important idea is that the meaning of the class and property definitions is described by the standard ontology modeling languages.
Custom properties are typically used with instances, in graph data, not in ontologies. The meaning of statements that are using custom properties is defined in the ontologies you build or re-use.
Remember that when you build an ontology, you are defining a language to be used for capturing the meaning of data. Languages for capturing the meaning of ontologies are already built – they are the standards, use them. Some modeling languages can be extended. SHACL, for example, can be extended with additional modeling constructs. If you need additional semantics, use the extension mechanisms.
Rule #2 of the Ontology Development: Use the industry standard language for describing your ontology. If you need additional language constructs to define semantics of your ontology, declare how you are extending the standard language.
- There are few, if any, OWL restrictions or SHACL property shapes that define classes
Creating these definitions requires careful consideration about semantics which is typically skipped when building classonomies.
- Classonomies are rarely modularized
I don’t want to say “never” because there may be exceptions, but I have not come across modular classonomies. While ontologies, to better support re-use, are often divided into smaller modules that can be used separately or together, this is not a common practice for classonomies. They are typically “all or nothing” proposition – even if there are other classonomies that cover the same domain of knowledge.
Every classonomy is created in isolation by a given community that is not necessarily committed to reusing the work of others or making it easy to re-use their work. This is evident in the BioPortal where most classes have multiple cross references to the identically named classes from other classonomies. There are well over a dozen classes called Activity. Do they have the same semantic meaning? Since the creators are not focused on re-use and do not practice semantic consistency, the answer can only be guessed.
Alternatives to Classonomies
The content of classonomies can serve an important role. The NCI thesaurus is clearly useful to the NCI and can be useful to others. Capturing it as an RDF graph is a great idea. Such thesauri can assist in the natural language processing, document tagging and other text analytics. They should, however, be clearly defined as thesauri or lexicons and not be deemed ontologies.
An obvious approach to turning such classonomies into thesauri is SKOS. SKOS is a standard ontology designed for capturing thesauri, classification schemes, subject heading lists and taxonomies in RDF. Instead of declaring classes, you create resources of type skos:Concept. These resources are connected hierarchically (child to parent) using skos:broader relationship. Unlike rdfs:subClassOf, skos:broader does not imply anything besides the fact that you can use it to create hierarchies. SKOS already provides standard built-in properties for concept definition, synonyms (called alternative labels in SKOS) and various notes (including examples). SKOS can be extended by creating a subclass of skos:Concept and defining additional properties for it e.g., a class NCI Term with a property UML_CUI.
If the NCI Thesaurus was provided as a SKOS taxonomy, there would be no misinterpretation of its meaning, content or intended use.
If SKOS is not a good fit, another option is to create a custom ontology for your content. It may contain one or more classes with the associated properties that you need in order to describe members of these classes. After you create this ontology, you create your terms as instances of your classes.
In Conclusion
Why do people create classonomies? I think this is an interesting question. I would like to hear your thoughts about the possible answers.
When I asked it myself, the answer I heard was “When we are not sure what something is, we make it a class – just in case”. To me, this answer does not make sense because by making something a class, you are making an ontological commitment. I believe the opposite should be the rule. If you are not sure, DO NOT make it a class. It is very easy to make it a skos:Concept or create your own class to capture terms in your domain and use that as the type for your terms.
It may be that developers of classonomies feel that some resources they are identifying could be classes and some could be instances, but they are not sure how to separate them. In such case, it is also best to create everything as an instance. Unless you know that a class will be used as a class and are able to clearly define distinguishing characteristics of the class members that are important and necessary for their intended use, there is negative value in calling it a class. If you are simply identifying a lexical term in a controlled vocabulary, do just that – define it as a term.
Another answer could be that Protégé makes it easy to create classes and class hierarchies and not so easy to work with and build hierarchies of instances. This can be solved as well. Use the tool that does not force you to create incorrect and unintended semantic definitions. There are a number of available options. TopBraid EDG-Vocabulary Management package is one of them. It makes it very easy to create SKOS taxonomies and thesauri. You can also use it to work with any data based on completely custom ontologies. And it can help you to convert a classonomy into a more semantically consistent, correct and easier to use knowledge graph.
Watch this video on how to customize SKOS taxonomies by extending SKOS with your own classes and properties.


