What is Reification?
While the name may sound complex, the concept is easy to understand. Reification is a technical term used in talking about possible approaches to making statements about facts captured in a graph. Let’s look at a simple example:
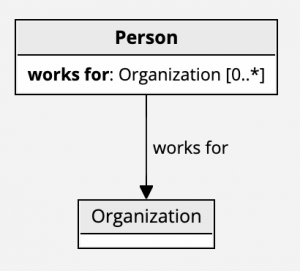
Consider a statement saying that Irene works for TopQuadrant. In this statement, we have two nodes and one link.

We can describe this type of information using a simple model that says that people can work for organizations.
We may, however, need to capture more information about Irene’s work at TopQuadrant, such as:
- What is Irene’s role at TopQuadrant?
- How long has she been with TopQuadrant?
- How do we know that she works at TopQuadrant – what is the source of this information?
- etc.
Why being able to capture such additional information is called reification?
Because answers to these questions are not independent facts, but rather facts that provide more information about the “works for” relationship between Irene and TopQuadrant. We are effectively turning the statement {Irene “works for” TopQuadrant} into a resource or an entity – so that we could talk about it.
In this example we demonstrate adding new facts about a relationship between two resources: Irene and TopQuadrant. However, approaches described here work exactly the same when adding information to a statement with a literal value e.g., if we needed to say something about Irene’s birth date.
Approaches to Reification
There are four main approaches:
1. Using named graphs
In some situations, named graphs can address the need to provide more information about graph statements.
Named graphs let us give a subgraph of a larger graph its own identity. A graph is a set of triple statements. It can be arbitrarily large e.g., all statements in your graph database.
We can say that some of the statements (a subset) belong not only to a larger, overall graph, but also to some smaller graph which we then name. As an example, each asset collection in TopBraid EDG is a named graph and it has its own information. Partitioning into subgraphs is a useful concept for a number of reasons. Let’s see how it could satisfy the needs in our example.
Let’s say we identify as a subgraph all information about TopQuadrant’s employees that we got from TopQuadrant’s website. We can then say that the source of these statements is TopQuadrant’s website. This approach can work well for information that is stably the same for a reasonably large group of triple statements.
However, it would not be sensible to use it to capture the start and end of Irene’s employment at TopQuadrant or her job title. Such information is specific to Irene, not to other people. If we decided to use this approach, we would have to create a potentially huge number of named graphs consisting of single triple statements.
2. Creating a new type/class
We may recognize that a concept of employment is important to us. Therefore, we decide to create a class Employment. This allows us to describe employment. We can say that employment has:
- Employee and employer
- Start and end
- Job role and so on
Our model (ontology) changes from the initial model.
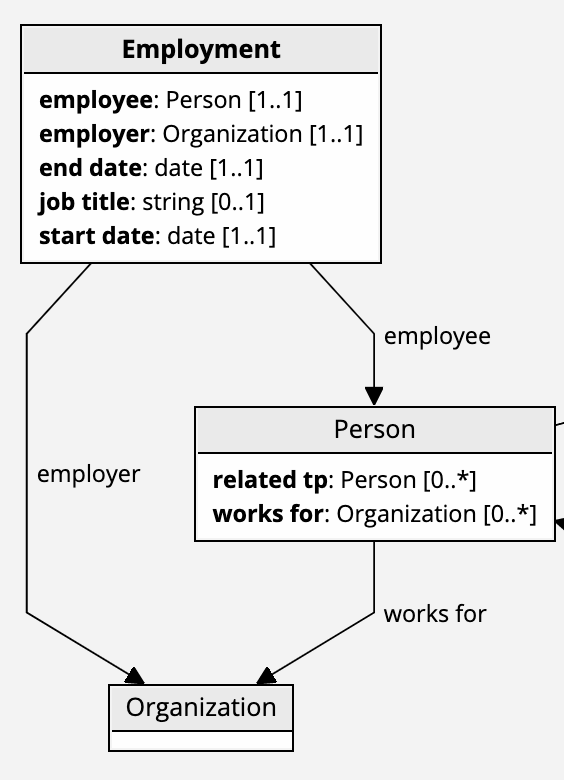
Note that the “works for” relationship is now redundant. We can determine who works for what organization by following Person <-employee–Employment–employer-> Organization links. With this, we do not need to store a direct connection between a person and an organization. In fact, it is best that this connection is not stored if our data is likely to change. Otherwise, we would need to worry about how to ensure that the redundant statements are synchronized e.g., if employee and employer links are removed, works for link needs to be removed as well. We would also need to worry about different ways of stating the information. If both options are open, some data may be using the Person <-employee–Employment–employer-> Organization option, while other data may be using the Person–works for->Organization option. It is best to agree that we will not store the direct “works for” statements.
Here is how our data will look now:
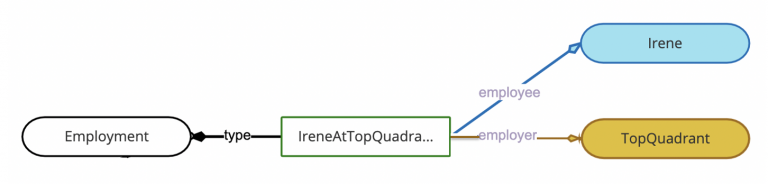
We could keep the “works for” property in the ontology and dynamically infer it. To do so, we can create a property value rule that will auto-infer the direct link based on the underlying two links. We could get even fancier and have two properties: works for and worked – with the corresponding logic to infer their values based on the absence or presence of the end date. Without the inference rule, queries that need to simply get information about who works where, without any details about employment, become a bit more complex.
3. Using RDF Reification
RDF reification is an approach that gives a persistent explicit identity to a statement and does so using the built-in RDF reification vocabulary.
Statements in a triple store database do already have an identity. But it is an internal identity. You can not refer to it in other statements. It is simply used by a database to manage triple facts, organizing them into different subgraphs. If you export data, you will not see the identity of each statement. It is fleeting and not interchangeable.
RDF’s native approach to giving an identity to a statement looks like this:
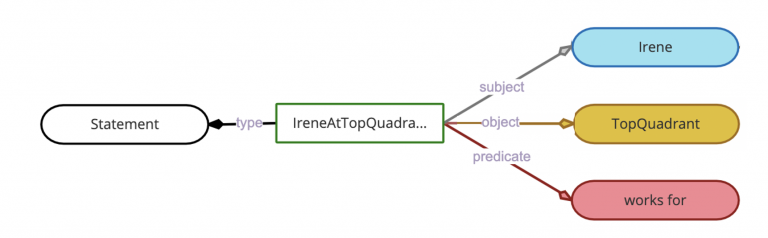
We create a new resource of type rdf:Statement, describe it in terms of its subject, predicate and object. We now have a new resource named IreneAtTopquadrant and we can make statements about it. It is understood that when we say something about IreneAtTopquadrant, we are talking about the “works for” relationship between Irene and TopQuadrant. In addition to the above data, we must keep our initial statement “Irene works for TopQuadrant” intact. It must continue to remain in the graph.
This is a more verbose/bulky approach than the previous one. We just added 4 triples in order to be able to say something about the one statement we already had. The previous approach adds only 3 triples and removes one – the statement saying that “Irene works for TopQudrant”.
We did not have to model anything, no new classes or properties are required. The built-in RDF reification vocabulary provided everything necessary to implement this approach. Sometimes, it will be seen as an advantage. However, not defining a model also has its minuses. Without a model, we can not describe what could or should be said about a given type of statement. For example:
- Source of the information is a generally applicable fact – we could potentially say what is the source of any statement.
- On the other hand, specifying a job title makes sense only for a statement about someone’s work. It does not make sense if we were, for example, talking about Irene’s place of birth.
Applications using this data would need to check for presence of a reified statement for each triple since there isn’t anything in the model that says where it may be present. Stakeholders preparing the data or trying to understand the data would not have the explicit expression of how the data should look like.
Of course, we could define subclasses of rdf:Statement e.g., Employment with the corresponding properties. Then, we would need to have a way to say that when a statement that describes “works for” relationship between a person and organization is turned into a resource, that resource must be of type Employment. If we do this, the solution starts to look more similar to approach #2.
One key difference compared to approach #2, is that with RDF reification we continue to store the “works for” statements and only add reifying statements where we need them. As a result, this approach is more economical when additional data about “works for” relationships is relatively rare. If we expect to have additional information in most cases, then it is better to create a new class with instances of employment.
4. Using RDF-star Reification
RDF-star (formerly known RDF*) is an extension to RDF that allows us to treat a triple statement as a resource – without using RDF vocabulary to declare this. When a product supports RDF-star, a triple can simply become a subject (or object) of another triple. This addresses the verbosity issue. Data does not grow in the same way as with the plain RDF reification.
RDF-star is not yet an official W3C standard, but work on the specification is well under way. TopQuadrant is one of the contributors to the specification document. In the meantime, many of the RDF technology vendors, including TopQuadrant, already implemented support for this concept.
With RDF-star, there is still a question of how to describe what can be said about a given statement. TopBraid EDG supports RDF-star style of reification. And it offers a way to describe in a model what kind of additional facts you can add to a given statement.
We will talk about how and when to do this in TopBraid EDG in the next blog.






