It’s becoming clear that Generative AI and Large Language Models (LLMs), such as ChatGPT, are likely to have a large impact on many industries. Their capabilities, strengths and weaknesses have many implications for people and industries that already use or are considering using Knowledge Graphs (KGs). In this post, we will explore the implications for and synergies between KGs and LLMs.
Generative AI is an umbrella term for all AI that creates brand new content – text, an image, even computer code – based on the learning from large amounts of existing data. An LLM is a subtype of Generative AI that takes in a text prompt and writes a human-like response. It is large because it is trained on massive amounts of data, like the entire internet. It’s a language model because its focus is predicting sequences of words.
LLMs can simulate “understanding” of the natural language and use it to present answers. They often produce the right or “close enough” answers. This is exciting and has a multitude of potentially useful applications. At the same time, an LLM can create responses that are wrong – sometimes in nuanced ways, other times in very obvious ways.
Knowledge Graphs, sometimes also called semantic networks, contain information about entities in the world, organized as nodes connected by relationships. The graphs capture data as well as semantics or meaning of data. We can distinguish different types of KGs – those containing basic data facts and those containing higher level semantic information.
ChatGPT is a chatbot built using the LLM technology. It hit 100 million users in only two months after its launch in late 2022. After the initial buzz and excitement about ChatGPT, many started to ask questions about the reliability and truthfulness of the content generated by ChatGPT and similar tools.
We will discuss how KGs can help address these issues, but, first, let’s consider what causes the issues.
Why LLMs Outputs Are Unreliable For Mission-Critical Tasks
LLMs don’t grasp the true meaning or full extent of accumulated knowledge. They work in a way different from a person who uses his full understanding of a topic to compose an answer. A good analogy is to consider differences in how a person and a trained image recognition model could recognize that an image contains a dog:
- A person has a mental model of a dog. They know it is an animal, a live organism with certain behaviors and a certain size and shape characteristics. They take all of this into consideration e.g., an animal on a leash or an animal chasing a cat up a tree is likely to be a dog.
- An image recognition model doesn’t know anything about dogs. It has been trained, using many images, to associate certain combinations of pixels with “dog.”
The same applies to answers generated by an LLM. These answers are simply the most statistically likely sequences of words. LLMs do not have a mental model or an axiomatic knowledge of the world. They can’t separate real from imagined, truth from fiction, leading to surprising consequences. Recognition of this phenomenon prompted creation of a new term: AI hallucination. As defined by Wikipedia, an AI hallucination is “a confident response by an AI that does not seem to be justified by its training data”.
For example, a hallucinating chatbot with no knowledge of Tesla’s revenue might internally pick a random number (such as “$13.6 billion”) that the chatbot deems plausible, and then go on to falsely and repeatedly insist that Tesla’s revenue is $13.6 billion, with no sign of internal awareness that the figure was a product of its own imagination. You could imagine how damaging this could be if one relied on this figure without questioning it.
At the end of 2022, Brian Hood, mayor of a town in Australia, became concerned about his reputation when members of the public told him that ChatGPT had falsely named him as a guilty party in a foreign bribery scandal involving a subsidiary of the Reserve Bank of Australia. Mr. Hood did work for the subsidiary, but was the whistleblower in the bribery case and was never charged with a crime. He is now preparing a defamation lawsuit against ChatGPT’s provider, OpenAI.
LLMs are known for inventing facts, events, books and people. When asked a question, it makes an educated guess on the topic and “creatively” fills the information gaps the best way it can, drawing conclusions from the statistical model that is created through training. Users testing ChatGPT complained that the bot often seemed to “sociopathically” and pointlessly embed plausible-sounding random falsehoods within its generated content.
This happened to me when during one conversation ChatGPT twice “forgot” who it was and very confidently claimed to be human, inventing a name and a background for itself. A colleague who asked ChatGPT to generate some code using a specific library, discovered that while ChatGPT produced sensibly looking code, the code was using a Java class that didn’t exist in this library. It used the Builder pattern that is now very popular in Java. However, this particular library didn’t support it. ChatGPT simply made it up.
OpenAI announcing GPT-4 acknowledged these issues by saying:
“Despite its capabilities, GPT-4 has similar limitations as earlier GPT models. Most importantly, it still is not fully reliable (it “hallucinates” facts and makes reasoning errors). Great care should be taken when using language model outputs, particularly in high-stakes contexts, with the exact protocol (such as human review, grounding with additional context, or avoiding high-stakes uses altogether) matching the needs of a specific use-case.”
Today, analysts consider frequent hallucination to be a major problem in the LLM technology and, more generally, in all Generative AI technologies. Knowledge graphs can help solve this problem and improve the reliability of LLMs.
How Knowledge Graphs Can Improve LLMs
ChatGPT and other LLMs reflect their training data, which may include noise, biases and different opinions. They also have a tendency to invent facts or “fib”. This is because ChatGPT doesn’t actually have a knowledge base of facts. Instead it has a language model generated through training. One could say that inventing facts is not really a bug of LLMs, but a feature. This technology is designed to predict a likely response – that is, when an LLMS is given, as a prompt, a beginning of a sentence, it can complete the sentence, predicting what is most likely to come next.
ChatGPT is very good at producing a first draft, but everything it tells you must be double-checked. Because you can never be certain how an LLM generated any specific text and what its response is based on, you can’t fully trust in. Depending on the application, this can be a very serious issue. Providing an LLM with a knowledge base can enhance the accuracy and relevance of its responses.
Representing mental models and knowledge in general is what KGs excel at. A KG modeled in RDF can represent meaning with unlimited richness and flexibility. As a curated set of facts, a KG can provide constraints to an LLM that can improve the quality of its output. Essentially, in doing this, we are applying epistemology to the generated content in order to flush out the truth. You can fully trust a KG because you can know what information it contains, the facts you built into it, how it can answer queries and what it can infer or reason. This makes KGs important to the progress of the LLMs and other generative AI technologies.
There are horses for courses and, for some applications, you may use just one of these technologies, but LLMs and KGs can be even better together! People and organizations who organize their knowledge as a KG will have a leg up in an AI-driven world.
To realize this future, there is a need for more well curated KGs. Interestingly enough, LLMs can be very useful in assisting people in the creation of knowledge graphs.
How LLMs Can Help Generate Knowledge Graphs
Today, products like TopBraid EDG can help you create knowledge graphs from a variety of structured data such as spreadsheets. However, much of our information is in text. Until the rise of Generative AI, technologies for extracting structured facts from text were hard to use and unimpressive. LLMs already demonstrated that they can do better.
Most of us have now seen how you can give ChatGPT a prompt in natural language and get an answer. In addition to returning an answer in natural language, it can be instructed to format the answer in other, more structured ways, like a table, a graph or even program code. This opens up the possibility of using an LLM to extract information from text and create structured data in a desired form, e.g., a taxonomy, context map, tabular dataset, or an RDF KG. The input can be any piece of text. You need to provide:
- A prompt giving ChatGPT instructions on how to format the output.
- A prompt can contain information in a textual format from which to generate the output. This isn’t always necessary since ChatGPT has been primed with a lot of information. But you may want to provide information from a document that is private to your organization or you may want ChatGPT to only use some specific text as opposed to other knowledge it may have.
Prompt engineering for LLMs is a separate topic that we will not cover in detail in this post. ChatGPT already knows about RDF. Thus, a user can simply say in the prompt:
“Generate an RDF rendition of the following using Turtle Notation.”
Then, provide the text input from which to create the output.
Output formatting instruction should also say:
- what ontology to use and
- how to generate URIs for resources
For example, you may use as input the following text describing one of the main characters in the HBO television series Succession:
“Logan Roy was born into humble circumstances in Dundee, Scotland on October 14, 1938, shortly before the outbreak of the Second World War. He grew up in poverty with his older brother, Ewan Roy, and his younger sister, Rose Roy.”
ChatGPT will recognize and structure facts about Logan Roy –his birth date and place, his sister and brother. If you don’t provide it with predicates and classes to use, it may generate them, but, typically, you want to use already existing ontology. You can add to the prompt a direction to use an ontology ChatGPT already knows about e.g, “use terms from Schema.org,” then ChatGPT will know to use predicates like schema:birthplace in the output. You are not limited to ontologies ChatGPT already knows about. You could also provide your own ontology in the prompt. And you could direct ChatGPT to extract only certain specific facts.
With this, nearly anyone can generate graphs from text. Or populate a taxonomy. Technical skill is no longer a limiting factor, although outputs generated by an LLM will still need to be reviewed and validated. A tool like TopBraid EDG with its built-in support for workflows and curation can facilitate this process very effectively.
This is big: Service providers charge a fortune to have armies of analysts populate taxonomies and classify data. That human effort can be reduced to a fraction of resources needed, lowering the cost and speeding time to delivery.
Instead of armies, you will need a few analysts to provide the right parameters to the LLM and to check the output. Much of the work for populating the knowledge base could now be automated. Adding integration with ChatGPT into your information management environment can minimize the need for prompt engineering. In the below example from TopBraid EDG, a user simply needs to provide text as input for taxonomy creation.

The resulting taxonomy in SKOS contains extracted resources and their relationships.
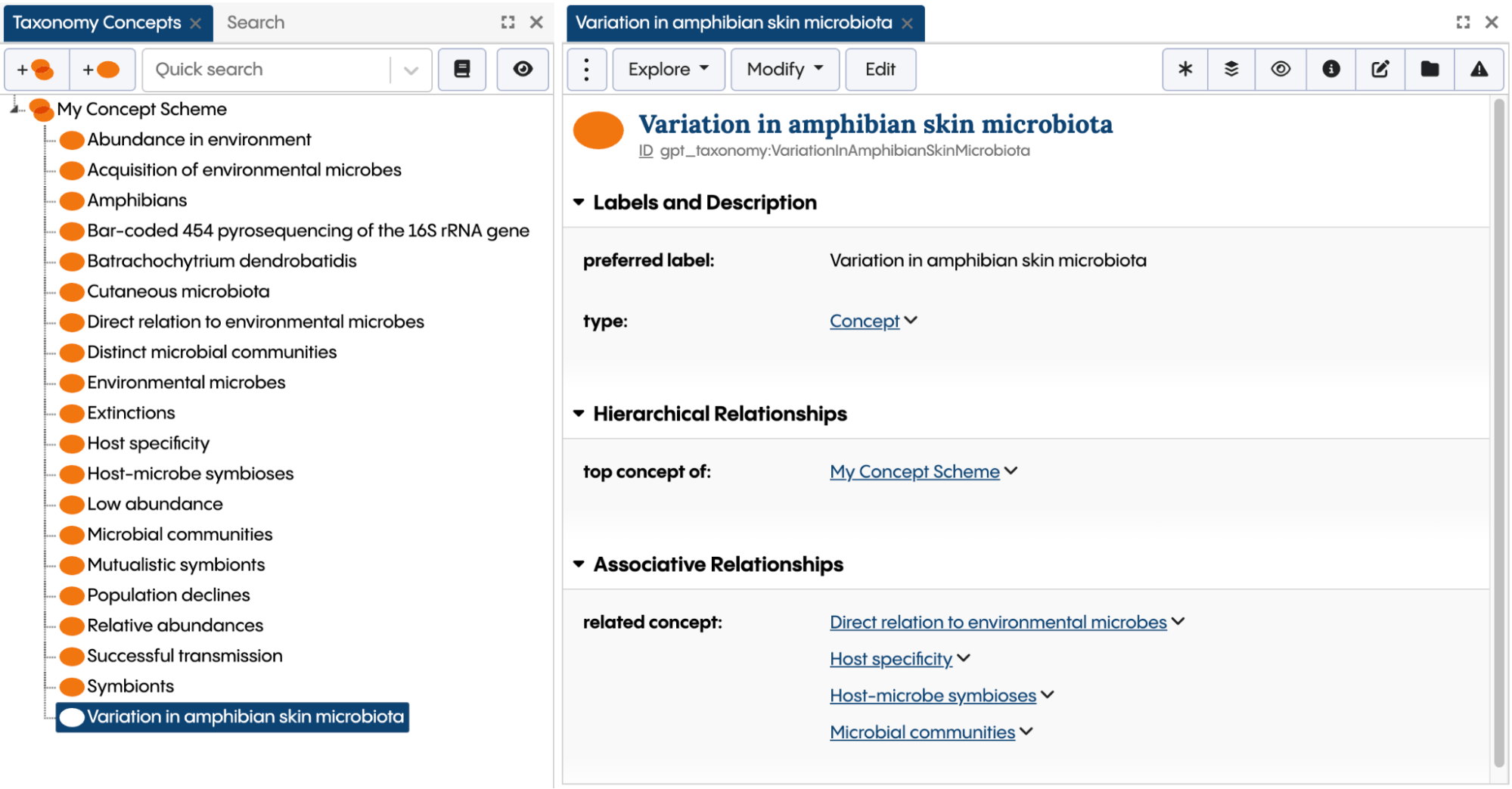
It is also possible to use your own ontology to auto-generate prompts. For example, if you have a property “birth date” with xsd:date in your ontology, your KG-based tool could, based on the user selection or other criteria, auto create a prompt saying “From the following text, extract the birth date in the following format.”
In the integration of Topbraid EDG with ChatGPT, prompts are auto-generated from any ontology to fetch all relevant properties. This is illustrated by the next screenshot where ChatGPT is directed to generate a KG about the Kennedy family from text, creating instances of the selected class – in this case, the Human class. In a prompt that is created behind the scenes, ChatGPT is passed a list of properties to populate from text.
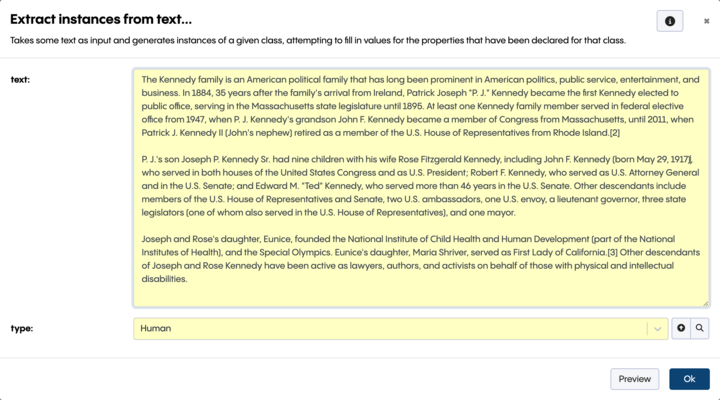
You can see below that a resource was created for each of the 8 people mentioned in the text. Note the correctly populated first, last and full names, date of birth and family relationships for one of these people – John F. Kennedy.
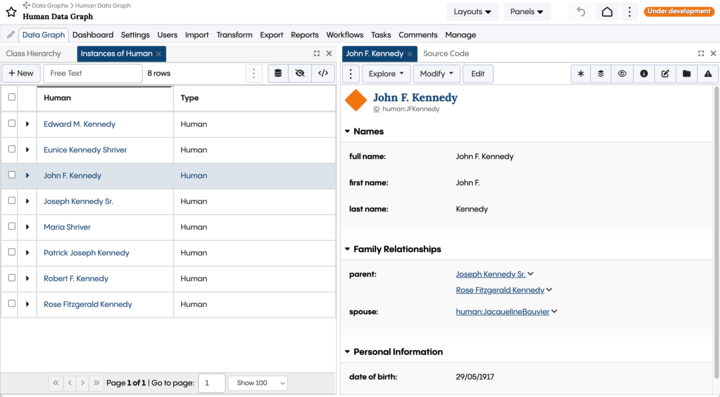
In addition to creating brand new resources, LLMs can also help with enriching information about resources that already exist in your KGs. For example:
- They can add descriptions for resources. This may include drafting summaries from and for documents. In small quantities, document summaries are a simple task. However, at scale, document summary creation can be an overwhelming project. LLMs drastically change the efficiency of how summaries can be created.
- They may be used to suggest properties for classes in your ontologies.
- They may be able to assist in generating mappings between KGs.
- They could be used to translate information into another language.
Example below shows how ChatGPT can help with translation by generating labels in additional languages for already existing resources.
In the next screenshot we see one of the generated German labels.

As previously noted, irrespective of how helpful are the automations made possible by ChatGPT and other LLMs, we must not forget the need for human curation – it is important that the overall workflow combines automated generation with the review and governing of the generated content.
How LLMs Can Support New Ways of Interacting with KGs
KGs can be queried using query languages. SPARQL is the de jure standard with wide support. Many products, including TopBraid EDG, also support GraphQL. In addition, products often provide search and browse user interfaces that generate queries behind the scenes. However, in some cases, users may want to interact with a knowledge base using plain language. A tool like ChatGPT can help. Since it can generate text in different formats, it could potentially act as a translator from natural language to a structured query.
Conversely, if needed, an LLM could provide a response as a well written and easily consumable text – acting also as a reverse translator from structured text into a more natural freeform. In some situations people would prefer an answer in natural language, instead of a table of query results.
Combining these capabilities can result in very interesting systems that offer intuitive and easy to use interfaces and provide answers that are guaranteed to be accurate.
In Summary
LLMs can significantly lessen the effort required for many tasks. They can be a great productivity tool and a workforce multiplier. However, LLMs don’t understand the true meaning of things and their output can be untrue. Given this, they need humans to supervise and validate their output for critically important tasks.
One example of a critically important task is creating corporations’ controlled vocabularies. These relatively small but important sets of data can have an outsized impact on operations and need strong controls and consistency brought to them. Controlled vocabularies, as part of organization’s knowledge, are often represented as KGs to make it easy to use them in myriad ways in different systems and processes. While LLMs don’t understand meaning and can’t be fully trusted to define those vocabularies, they can be an effective tool in assisting with their creation.
Once you have a knowledge graph, it can be used to inform, focus, filter and control Generative AI. Providing an LLM with a knowledge base will enhance the intelligence and reliability of its responses, making it a better fit for mission critical tasks. Going forward, we envision future systems that will combine the prowess of the LLM and KG technologies. This future is very near! Organizations that invest in creating Knowledge Graphs will have a leg up on the competition when it comes to reaping benefits of the Generative AI.






