Exploring EU Open Data Portal
Recently, we have been hearing from a number of organizations in Europe and the United States that want to make available a catalog of datasets similar to the EU Open Data Portal. In response to this interest, we decided to write a series of blogs on this topic:
- This first blog is about the EU Open Data Portal, its capabilities and its use of RDF technologies and, specifically, DCAT vocabulary.
- Our next blogs will demonstrate how TopBraid EDG, out of the box, can deliver a practically identical portal.
First, let’s take a look at the EU Open Data Portal. It lets us search for datasets by entering search terms of interest e.g., population.
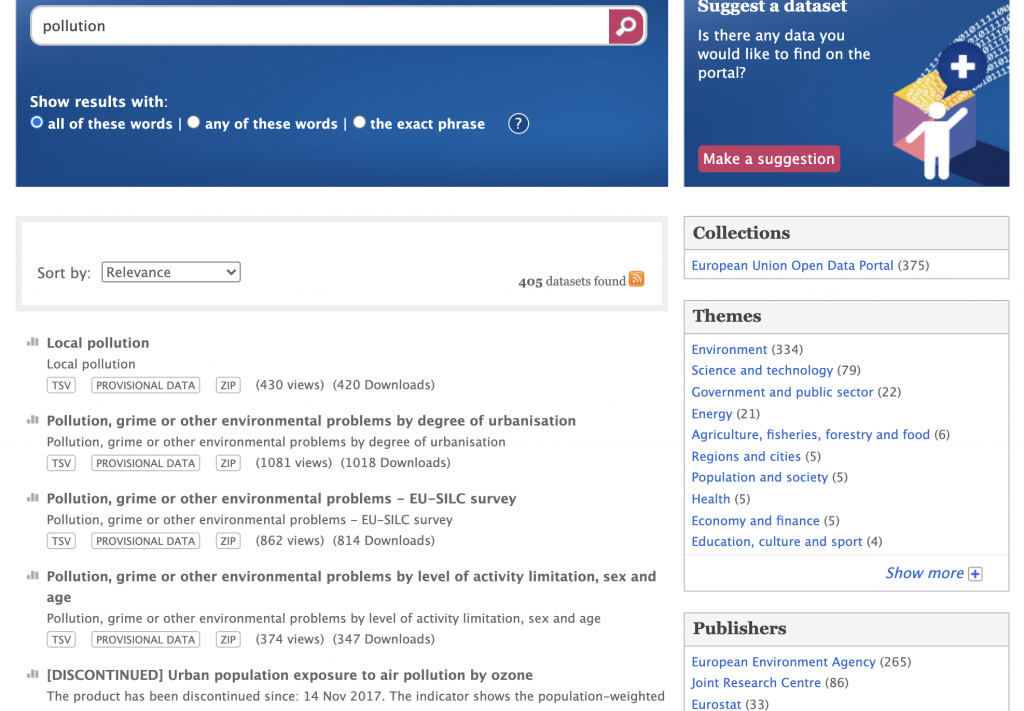
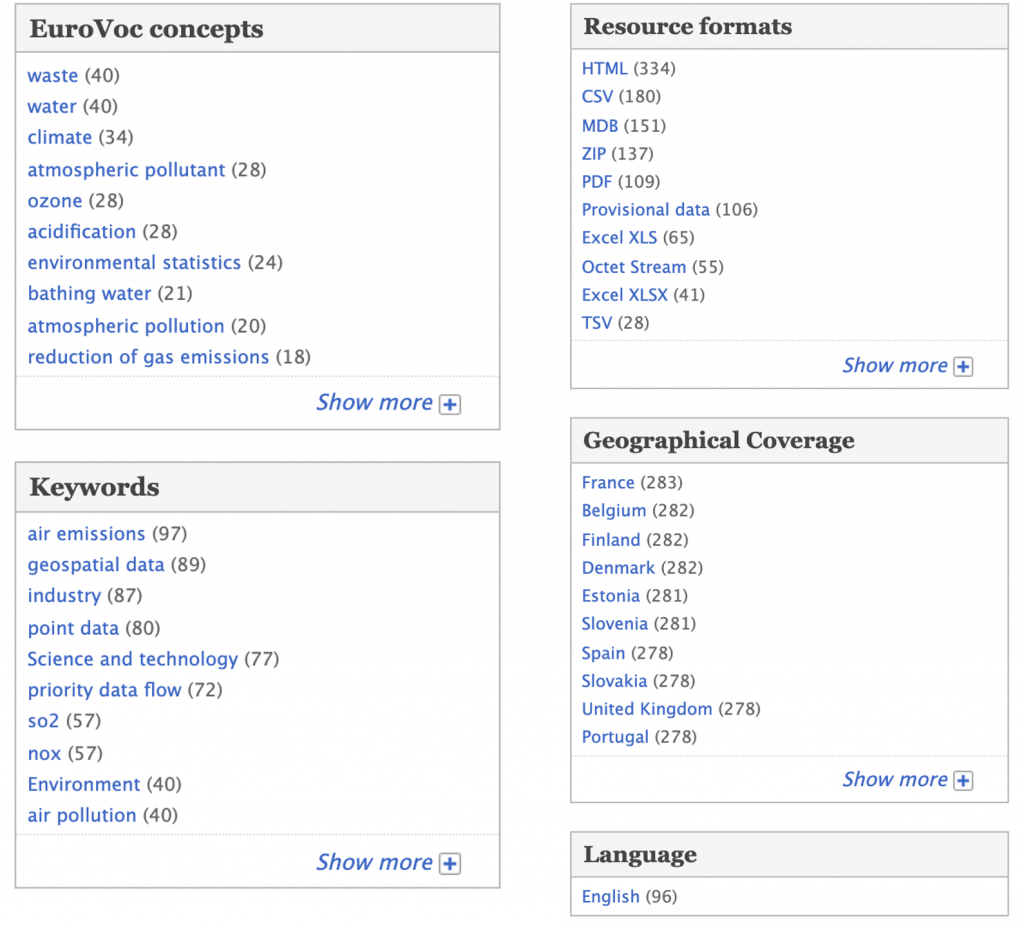
For each of the matching datasets, we see a name, description, file formats available for download and a number of user views and downloads. We can then further narrow the list of datasets by using facets presented on the right. In addition to the Themes and Publishers facets shown in the screenshot above, there are also additional facets as presented below. They let you narrow results by the EuroVoc concept a dataset is tagged with, file format, a keyword, a country for which data is included in a dataset and a language of a dataset.
If we click on a dataset of interest, we see more information, including the download links.
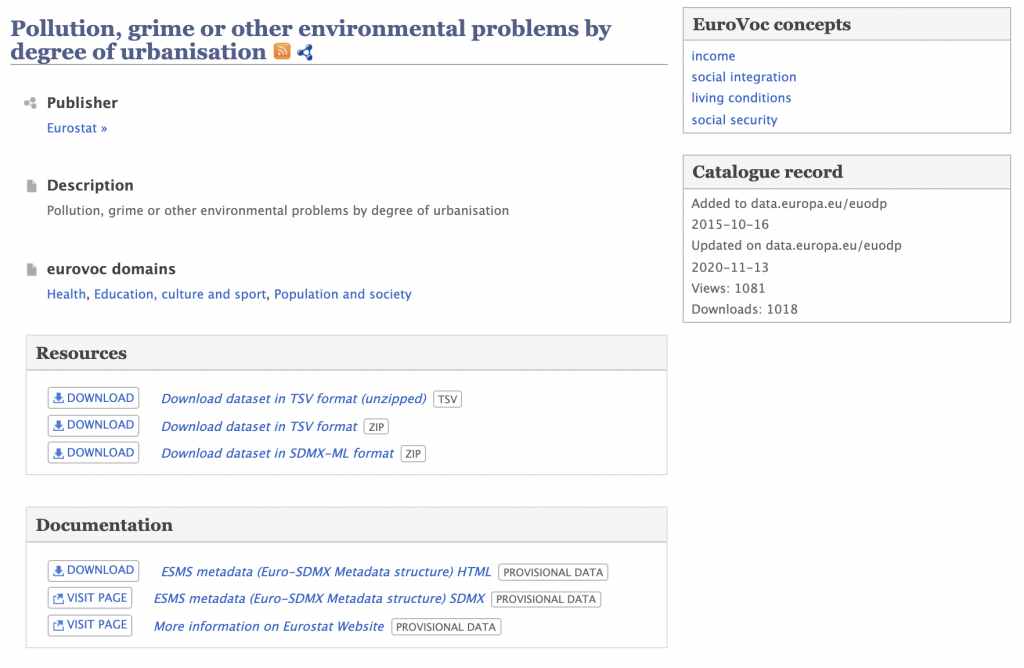
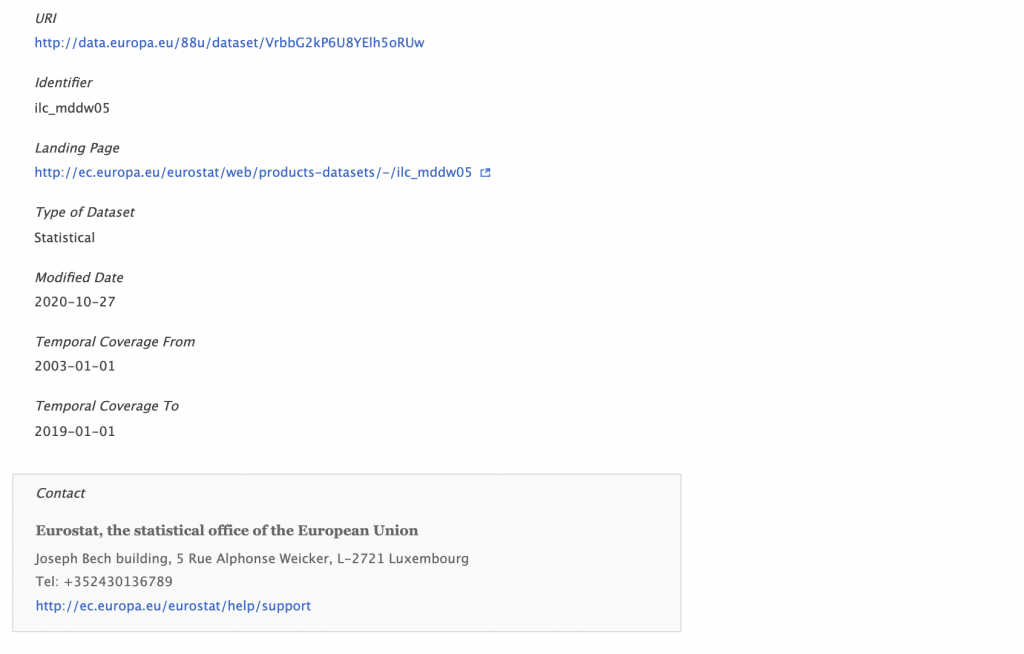
These features are available in TopBraid EDG out of the box and in the next blogs we will demonstrate them using datasets from the EU Open Data Portal.
RDF icon to the right of the title of each dataset lets us fetch a description of the dataset in RDF. This, and the availability of a SPARQL endpoint, is what makes the EU data open. RDF uses a profile of DCAT vocabulary. By profile we mean that DCAT is used a certain way. We will describe exactly how in the rest of this blog. DCAT is, on one hand, quite extensive with many properties to choose from and, on the other hand, has fairly weak semantics with respect to what some of the property values may be. Thus, different organization that decide to use properties and classes from the DCAT namespace may use a different subset of properties and use them in a somewhat different way.
For example, property dcat:theme is described as “A main category of the resource. A resource can have multiple themes.” It is recommended that “the taxonomy of themes is organized in a skos:ConceptScheme, skos:Collection, owl:Ontology or similar, which allows each member to be denoted by an IRI and published as Linked Data.” No other recommendation is given so this could be a controlled vocabulary of user’s choice. EU Open Data Portal, uses as themes resources of type http://inventory.ec.europa.eu/DataThemes. There are 13 Data Themes.
Use of DCAT to describe Datasets in the EU Open Data Portal
Let’s take a look at the RDF describing the dataset in the screenshot above. Downloaded files are serialized in RDF/XML. We are showing the equivalent Turtle serialization as it is more readable.
Each dataset is a resource of type dcat:Dataset with an autogenerated URI. We have broken information about this dataset into 7 groupings – as shown below:
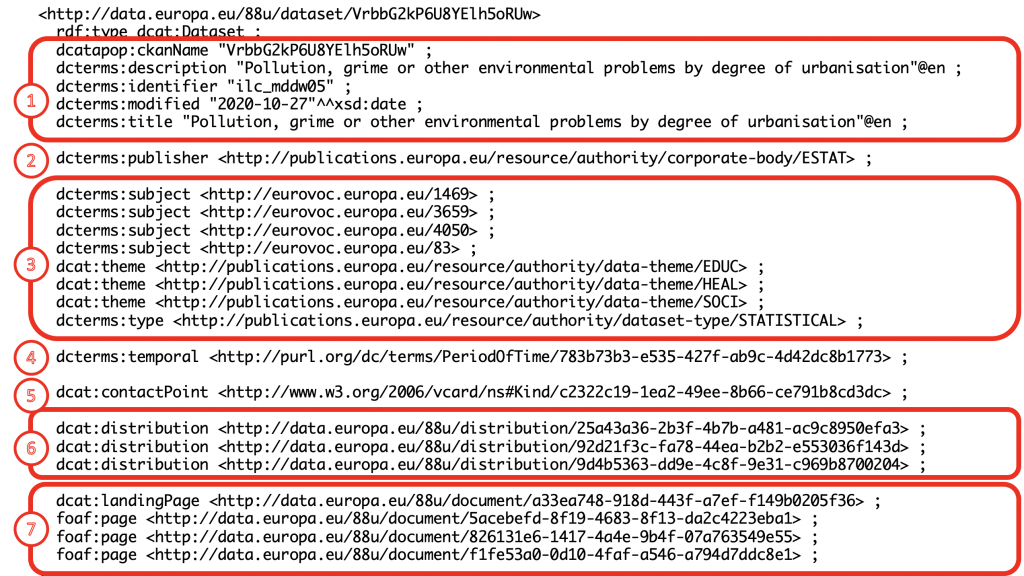
1 – Title, description, IDs and various other metadata with literal (text, date, integer) values.
2 – Link to the organization that published the dataset. This is used as a facet.
3 – Various categorizations most of which are also used as facets – Themes, Eurovoc concepts and dataset type are shown above. For some datasets Country and Language are also captured.
4 – Temporal period covered by the dataset’s data i.e., coverage from and to date
5 – Contact information for the dataset
6 – Distribution information – this is where download links and formats are captured
7 – Web pages providing additional information
As you can see, information in bullets 2 through 7 is captured as various additional resources. We will examine each of them one by one.
2. Publishers
Publishers are resources from a controlled vocabulary (reference data, or an authority file) capturing various government agencies in the EU that provide the datasets.
3. Themes, Subjects, Types, Spatial, Language
Themes, subjects and types also come from controlled vocabularies.
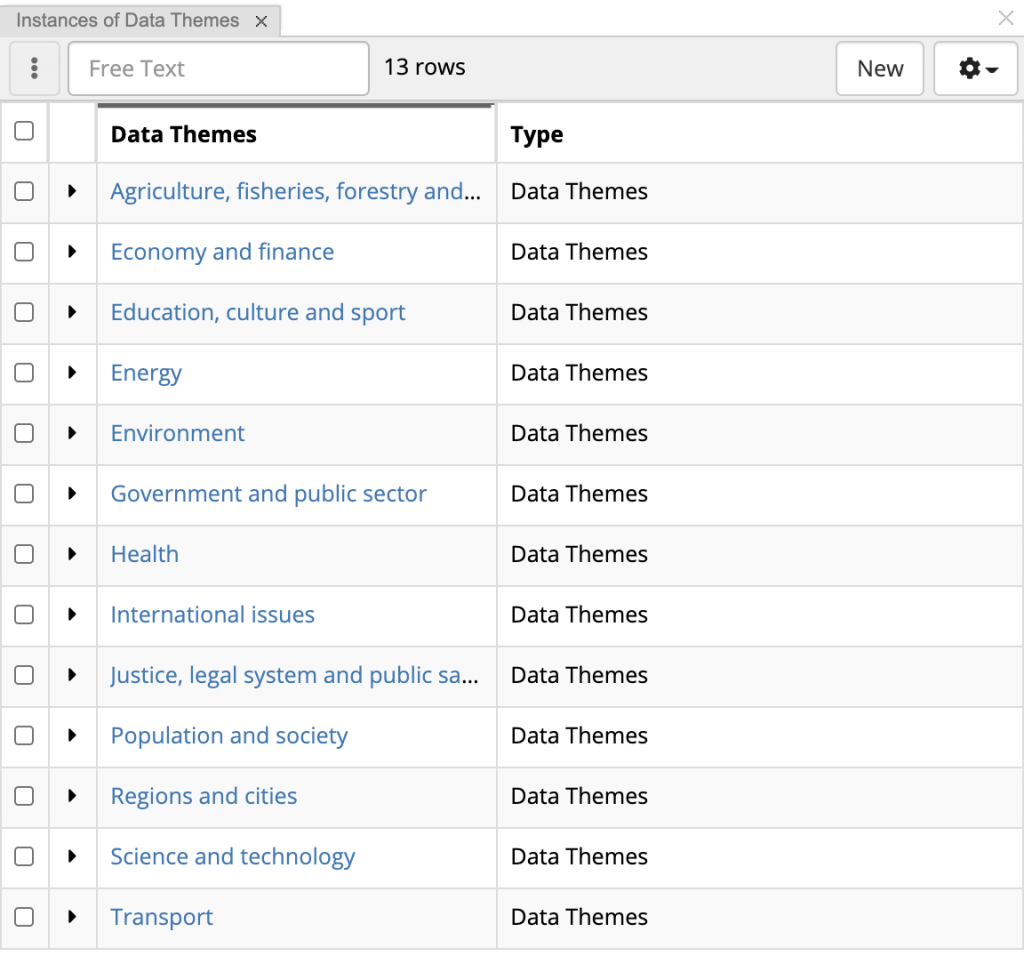
Themes is a flat list of just 13 Data Themes shown below in TopBraid EDG. As a facet on the search page, these are called Themes. When displayed on a page with dataset’s information , they are called Eurovoc domains.
Subjects come from a hierarchically organized vocabulary (referred to as Eurovoc) with 1763 concepts. DCAT says that dcat:theme is a subproperty of dcterms:subject which would make all Data Themes also subjects.
Types is even a smaller list. Because it is very small, it is not used as a facet and is simply displayed as Type of Dataset on the dataset’s page.
Our example dataset is not associated with any country. If it was, this would be captured using dcterms:spatial property. Values of this property come from an authority file of countries which uses ISO codes to form URIs e.g., http://publications.europa.eu/resource/authority/country/NOR for Norway.
Some datasets also have language information. This is captured in the dcterms:language property. Languages are in a controlled vocabulary (authority file) that uses ISO 3 character codes to form URIs e.g., http://publications.europa.eu/resource/authority/language/ENG for English.
Another facet that we see on the search page is Keywords. Keywords are stored as text strings using dcat:keyword property.
4. Temporal Coverage
This is where dataset information starts to get more complex since it is no longer directly associated with each dataset. Rather, intermediate resources are used.
As shown below, temporal information is actually captured using a resource of type dcterms:PeriodOfTime. It then uses properties from the Schema.org namespace – start and end dates.
In the screenshot below and in the examples that follow, we show a resource that is used as an object of a statement underlining it in red e.g., resource that is used as a value of the dcterms:temporal property for our dataset. We then show it again, also underlined in red, as a subject with its associated information e.g., start and end date. Thus, you will see the same resource twice with a red arrow connecting both occurrences to make this clearer.
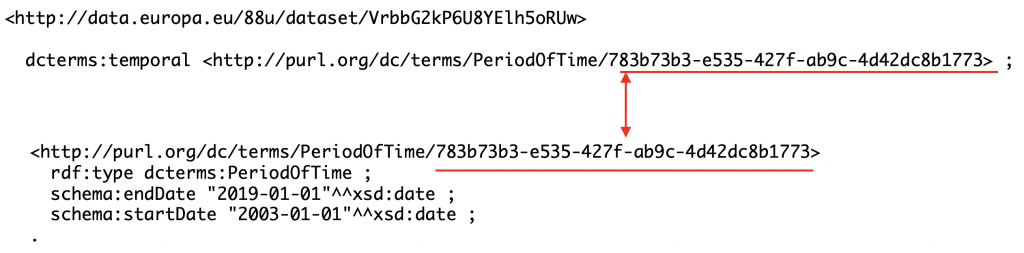
This approach would make sense if period of times were re-used. In other words, if there was a specific URI for a period 1/1/2003-1/1/2019 and each dataset for this period used this URI as a temporal value. However, this is not the case. Each time a Period of Time is used in the EU Open Data Portal, it is a different resource with a different URI – even if start and end dates are the same.
Thus, creating a resource for this information does not add any value and simply makes information more complex – requiring one to do an extra “graph hop” to get to dates for a dataset.
DCAT does recommend the use of Period of Time resources for the temporal coverage. However, it is fairly clear that the intention is to re-use periods of time. As you will see in the section below, this problem occurs in multiple cases.
Why does it happen? The URI generation strategy in the EU Open Data Portal is based on the randomly generated GUIDs. When a secondary resource such as a time period or a contact is created, the software simply generates a new random URI without first checking if such resource already exists. This is easier to do than trying to find a match. However, this defeats the purpose of having resources and it is better to simply keep the information as literal values directly associated with the dataset.
The use of Schema.org properties also diverges from the DCAT recommendation that the start and end of the interval SHOULD be given by using properties dcat:startDate or time:hasBeginning and dcat:endDate or time:hasEnd, respectively.
5. Contact Information
Contact information is even more complex. It also contains malformed URIs.
Points of contact are resources of vcard:Kind type. This follows DCAT recommendation. However, contact resources are not re-used. Thus, the motivation for the recommendation is not supported.
Further, DCAT addresses a general situation where it is possible for datasets to have multiple points of contact. In such situations, it makes sense to create contact resources and capture their information separately from a dataset. However, in this data, there is always one contact per dataset. Thus, this information could be associated directly with each dataset. In the screenshot below, you see a resource of type vcard:Kind used as a point of contact.
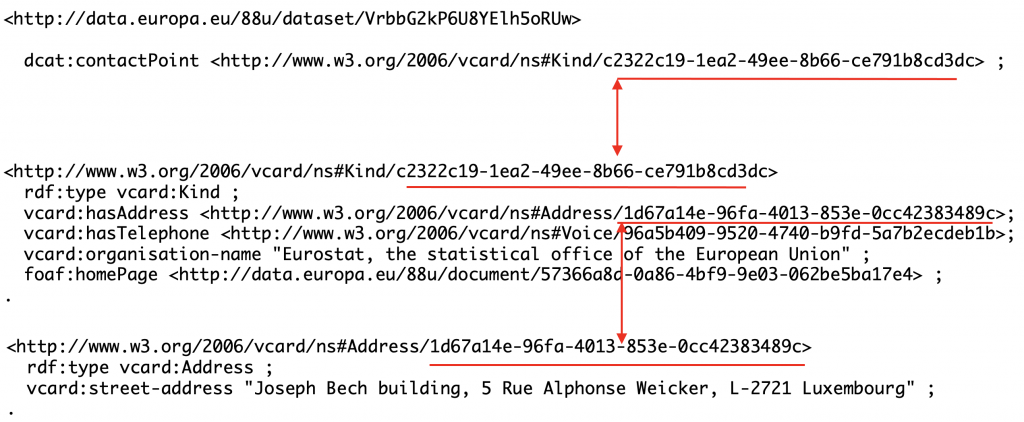
As shown in the screenshot above and the screenshots below, there is another level of indirection because Address is also a resource – of type vcard:Address, Telephone is a resource of type vcard:Voice and Home Page for the contact is a resource of type foaf:Document.
Again, as it is with the period of time, the same addresses, phone numbers and home pages appear multiple times and each time they are given a new URI. For example, since Eurostat is a publisher of many datasets, it is listed as a contact numerous times with the same address and phone number. Each time, it is given a different URI, its address, phone number and home page are also given different URIs. None of these are connected to the Eurostat resource that is a member of the controlled dataset of publishers.
Thus, this approach introduces resources that simply bloat and complicate information and are not re-used. For example, a query for finding all datasets for which Eurostat is a point of contact would have to depend on the textual match, which is highly unreliable. Indeed, we found variations in the organization-name strings that clearly refer to the same organizations.
Phone and home page resources have additional problems. You will see below the peculiar URI for the vcard:hasValue property of the vcard:Voice resource. It uses file:/// instead of http://.
This is because downloaded RDF does not contain a full resolvable URI. It only has a string without the URL scheme for resources of vcard:Voice type. To deal with this issue, when a downloaded file is opened, TopBraid generates a URI using location of the file and “file:” URL scheme. In our case, we put the dataset file in the workspace under TopBraid/ directory. This prevents such resources from being interoperable since generation of the URI is highly dependent on the location of the file.
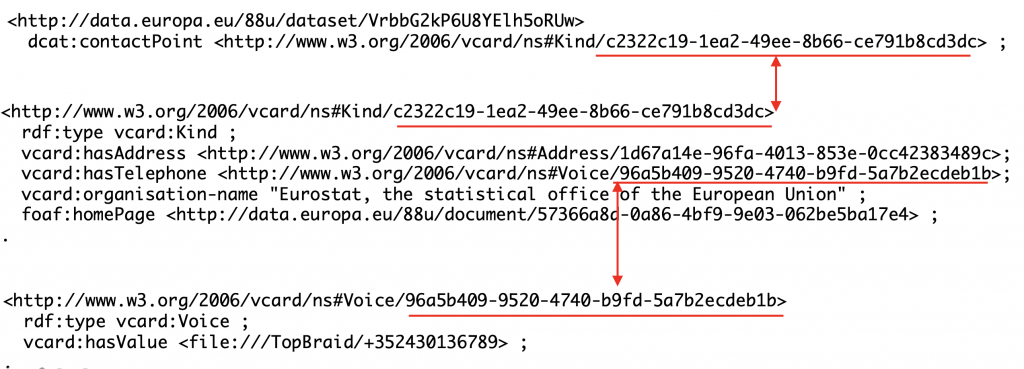
To make this clearer, we are showing below how this information looks like in the RDF/XML serialization downloaded from the portal. As you can see, the telephone number is a resource, but it does not have a valid URI since it is missing the URL scheme. Our guess is that it is an error.

The same problem is evident in the foaf:Document resource for the home page. Not only the same home pages (e.g., support page for the Eurostat) are captured using different URIs, but URL schemas are missing for values of dcterms:type and foaf:topic. For example, the value of foaf:topic in the downloaded file is simply <foaf:topic rdf_resource=”default_topic_foaf”/>.
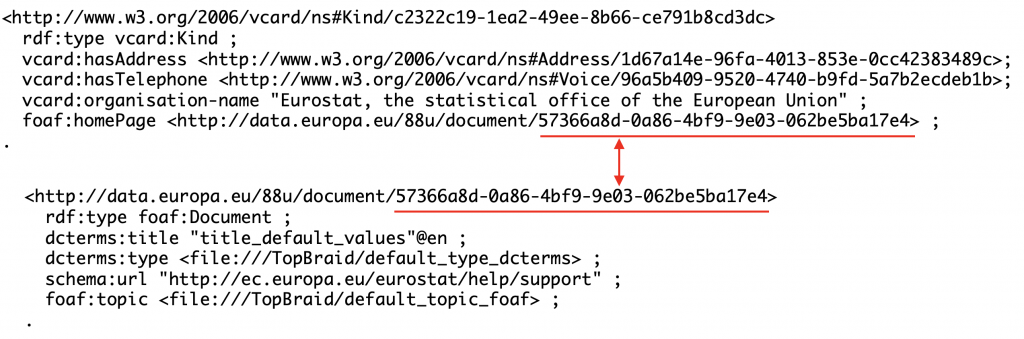
schema:url is used to capture the URL of the home page. Unfortunately, these values do not have the datatype xsd:anyURI which would make it possible to recognize it as a web link.
6. Distribution Information
Actual datasets (data described with the dataset records) is available as files of different format. Given this, it makes sense that separate resources are created to represent each file. These resources are of type dcat:Distribution. As shown below, they contain accessURL – a link where we can download a file. They also specify file format (using a small controlled vocabulary), type of license (also a controlled vocabulary). If a size of the file is available, it is also stored here using dcat:byteSize property.
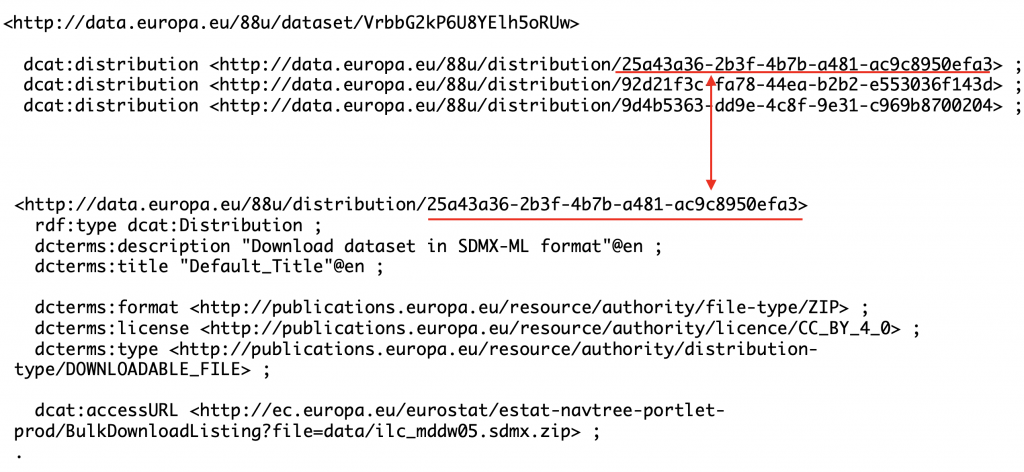
In most cases, this information includes title and description for the file being made available. However, titles are often not particularly meaningful – as shown above, and are not displayed in the UI.
7. Web pages
For each dataset, there are some web pages containing additional information:
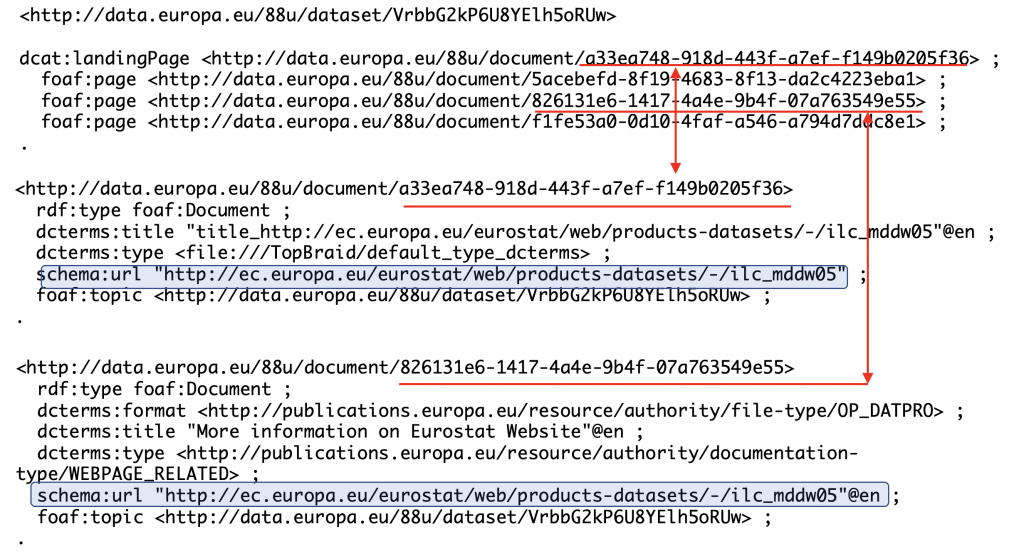
- The main page is captured as a foaf:Document resource pointed to by the dcat:landingPage property.
- Then, there are other pages which are also of foaf:Document type but are connected to a dataset using foaf:page property.
We see here information repetition issues similar to ones pointed out throughout this blog. As you can see in the screenshot below, the same web page is pointed to twice and each time it is represented as a resource with a different URI.
Catalog Record
There is also a Catalog Record for each dataset. It contains information about the number of views and downloads as well as dates when the dataset was added to the catalog or last modified. Decision to keep this information as a separate resource as opposed to directly as dataset’s property can be explained by a desire to separate “pure dataset information” from the information specific to its access and use within a particular catalog i.e., EU Open Data Portal.
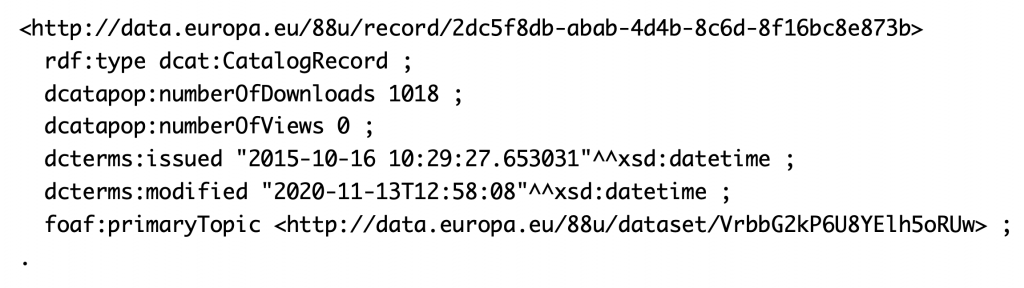
Number of view is always 0. When a dataset is displayed, number of downloads is used to display the number of views. Possibly, the portal makes no distinction between views and downloads and simply defaults to zero – at least presently. foaf:primaryTopic property is used to link the Catalog Record back to the Dataset.
Not provided for our example dataset, dcterms:acrrualPeriodicity is sometimes provided for datasets. It is captured directly for the dataset and uses a small controlled vocabulary – 14 periodicities.
In Conclusion
In this blog we have discussed in detail the functionality available in the EU Open Data Portal. In the next blog, we will show how to load these dataset descriptions in TopBraid EDG and search and browse dataset information using free text and faceted search.






