DCAT Data Catalogs with TopBraid EDG
Recently, we have been hearing from organizations in Europe and the United States that want to create a catalog of datasets similar to the EU Open Data Portal. In response to this interest, we decided to write a series of blogs about DCAT data catalogs:
- The first blog was about the EU Open Data Portal, its capabilities and its use of RDF technologies and, specifically, DCAT vocabulary.
- The second blog showed datasets from the EU Open Data Portal in a searchable interactive data catalog in TopBraid EDG
- This third blog discusses why you may want to base your catalog on the TopBraid EDG ontologies for describing enterprise data and how to align their use with DCAT.
Why use TopBraid EDG data asset model for your data catalog?
TopBraid EDG offers about 300 pre-built classes. Many of them describe different types of data assets. Others describe related objects in the enterprise – technology, infrastructure, business capabilities, stakeholders, etc. See our recent blog for an overview of EDG ontologies.
DCAT focuses narrowly on datasets and does not offer a rich framework for describing how datasets are used in an enterprise or across enterprises.
EDG automatically introspects, profiles and catalogs data sources. The auto-cataloging process uses EDG ontologies. For example, when cataloging a database it will use:
- edg:columnOf to connect a column to a table it belongs to
- edg:distinctValuesCount to capture the number of distinct values in a column
- edg:numberOfTables to capture the number of tables in a database
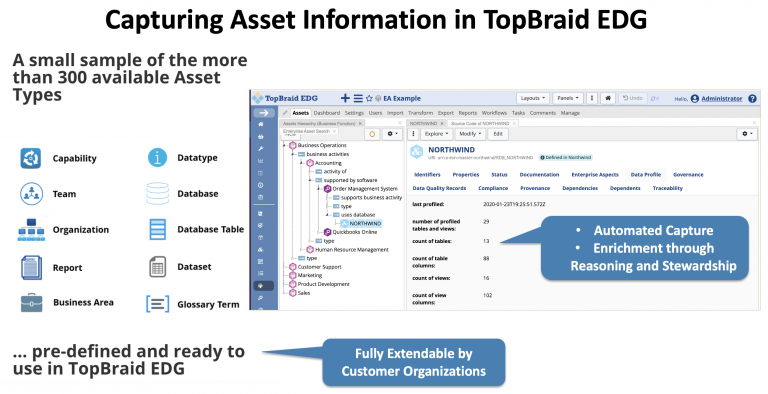
This means that properties populated automatically have special significance to EDG. In many cases DCAT does not offer an alternative to these fields.
Once datasets are cataloged, EDG offers many capabilities for enriching collected information:
- Catalog Enrichment
Rule-based inferencing and other algorithms will suggest additional connections. For an example of how this works, see our blog on connecting data assets to business terms.
- Consistent Organization
Data catalog’s usefulness depends on how well it is organized. A catalog must effectively integrate metadata from different data sources. TopBraid EDG helps you create well organized integrated data catalogs by ensuring consistent use of common controlled vocabularies e.g., reference datasets and taxonomies. To learn more on how EDG helps users to manage controlled vocabularies, see our Taxonomy and Reference Data Management solution pages.
- Trusted Data
Your catalog must be trusted in order to provide value. TopBraid EDG has built-in data validation to identify and fix errors in the information. Catalog curation is key to ensuring that collected information is well vetted. With EDG, stewardship responsibilities can be assigned and instrumented using workflows and other collaboration features.
In addition to the benefits listed above, TopBraid EDG provides a variety of the out of the box applications and APIs for interacting with the catalog:
- Faceted and key word search with facets auto-suggested based on the available data – see blog two in this series for an example of faceted search.
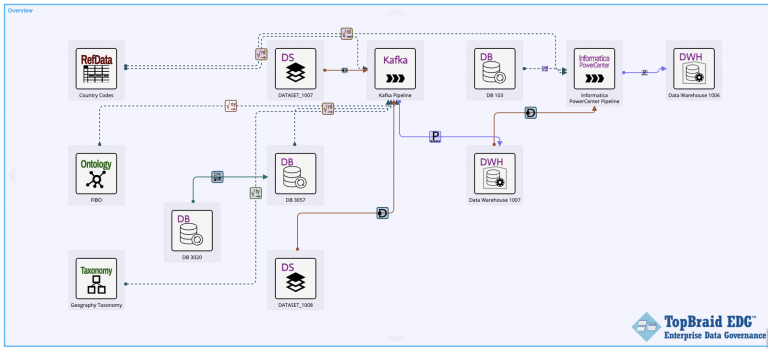
- Exploration of data lineage and impact – see the diagram below for an example of an interactive lineage diagram in TopBraid EDG.
- Parametrized SPARQL query and reporting.
- Full GraphQL access for read and write operations – for more information see our recent blog on querying TopBraid EDG with GraphQL.
How to align your use of EDG with DCAT
A dataset in DCAT is typically used to describe any data asset. EDG, on the other hand, differentiates between relational databases, database tables, NoSQL databases, groups or collections of datasets, datasets of a certain category (such as a spreadsheet) and other data sources. Each is represented as a class in the EDG ontology. These classes have some common properties, but they also have some unique properties. One could say that dcat:Dataset is closer to edg:DataAsset than to edg:DataSet – or at least, in between.
With this, one option is to simply use edg:DataSet for files and other EDG classes for databases and collections of datasets.
If, however, the use of dcat:Dataset as a type for your cataloged resources is important to you, you can extend EDG ontologies by saying that dcat:Dataset is a subclass of one of the EDG data asset classes. Decision on what to subclass will depend on your use of dcat:Dataset. Will it be limited to single files (if so, subclass edg:DataSet) or will be broader?
Adding a “custom” class as an extension of EDG ontologies lets you use all the pre-built features of EDG, yet maintain alignment with your own model – in this case, DCAT data catalogs model.
Your next decision will be about the use of properties. Broadly speaking, there are four categories of data asset properties in EDG:
- Properties automatically populated by EDG through the auto-cataloging and/or enrichment processes.
These properties describe the structure of a dataset and/or capture statistics about data e.g., number of unique values. In most cases DCAT does not offer an alternative to these fields. This means that you do not need to worry about alignment.
- Properties that are special to EDG because their presence is relied on in the user interface. The main example is label
TopBraid EDG recognizes either rdfs:label or skos:prefLabel as a “special” property – a name to be used in the UI displays and fo auto-completion. At minimum, you must use one of these labels in addition to dcterms:title. EDG will automatically populate them – unless you directly import RDF data. EDG also offers properties like edg:title and edg:name that can be used as alternatives to dcterms:title.
- Properties that are identical in their intent and semantics to properties used in DCAT and are not populated by any specialized EDG processing.
Their values are typically literals e.g., strings. edg:title is one example. Other examples are edg:description – an alternative to dcterms:description and edg:tag – an alternative to dcat:keyword. If your preference is to use DCAT properties, you can easily do so. Simply make sure that there is a property shape defining them. You could then deactivate edg: properties with the same name and/or purpose – to avoid any confusion.
- Properties that are similar in their intent but have different semantics than properties used in DCAT and are not populated by any specialized EDG processing.
Their values in EDG are often other resources of specific type i.e., they are relationships. In DCAT, however, they may be simply strings or resources of a more general type – because, unlike EDG ontologies, DCAT does not define a rich model of data ecosystem. For example, in DCAT one would use resources of type vcard:Kind as values of dcat:contactPoint to identify an organization that is a point of contact for a dataset. EDG offers a more specific property edg:contactOrganization which values are expected to be members of edg:Organization class. We believe that EDG approach is semantically more precise and would recommend using EDG properties. Having said this, you can choose in some or all cases to use DCAT properties instead of ones from EDG – simply, make sure they are defined and deactivate edg: properties with the same name and/or purpose.
In conclusion
Whatever level of alignment you decide to use, you can always export a “DCAT-version” of the information in EDG. If you are using edg: properties and want to export information in DCAT format, simply define transformation rules to generate DCAT properties. You can choose to run the rules on export.
If you want to be able to query for DCAT properties, use Property Value Rules in EDG. They will dynamically populate data in DCAT format, on demand. To learn more about the standard TopBraid EDG uses to describe and run rules, see this W3C specification. For an example of how to create and use Property Value Rules in EDG, see our user guide.
We hope you enjoyed this blog series. You may also want to watch our recent webinar about data cataloging.
Let us know if you want to discuss in more detail implementing data catalogs in general and/or, specifically, DCAT data catalogs!



