The main goal of creating an enterprise data fabric is not new. It is the ability to deliver the right data at the right time, in the right shape, and to the right data consumer, irrespective of how and where it is stored. Data fabric is the common “net” that stitches integrated data from multiple data and application sources and delivers it to various data consumers.
So, what makes the data fabric approach different from previous, more traditional data integration architectures? The key differentiator of a data fabric is its fundamental reliance on metadata to accomplish this goal. Implementing a data fabric means establishing a metadata-driven architecture capable of delivering integrated and enriched data to data consumers. To emphasize this point, Gartner coined the term active metadata.
Data fabric relies on active metadata.
Metadata describes different aspects of data. The more comprehensive the sets of metadata we collect, the better they will be able to support our application scenarios. Traditionally, metadata categories have included:
- Business metadata – provides the meaning of data through mappings to business terms.
- Technical metadata – provides information on the format and structure of the data such as physical database schemas, data types, data models.
- Operational metadata – describes details of the processing and accessing of data such as data sharing rules, performance, maintenance plans, archive and retention rules.
More recently, a new category of metadata became important – Social metadata. It typically includes discussions and feedback on the data from its technical and business users. Business metadata has evolved beyond just mapping to terms to now encompassing ontologies to better assist with interpreting data’s context and meaning.
How is active metadata different from passive metadata? Gartner defines passive metadata as any metadata that is collected. Some Gartner analysts equate active metadata with metadata that is being used. By use, we mean use of the metadata by software (such as software components within the data fabric) in support of a broad range of data integration, analysis, reporting and other data processing scenarios. Other analysts push this concept further and say that active metadata is created by the data fabric by analyzing passive metadata and using the results to recommend or automate tasks.
Irrespective of the exact definition of active metadata, the underlying premise of the data fabric is that the optimal solution for the delivery of the right data in the right shape is to leverage its metadata. For example, the data fabric may use metadata to:
- recommend already available data integration pipelines so that organizations don’t create overlapping pipelines that essentially serve the same purpose.
- deliver “just in time” pipelines for upcoming requirements based on the analysis of metadata from previous data pipelines.
- recommend to data engineers the best data delivery style for a given use case
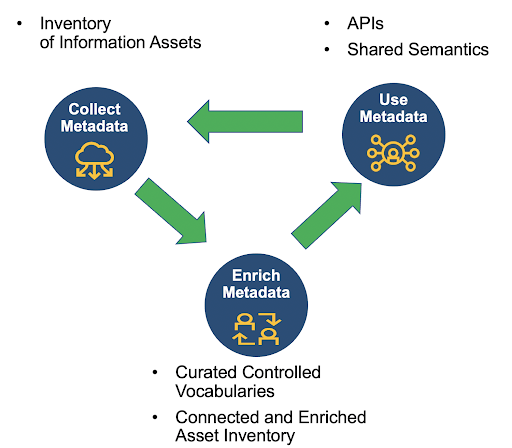
To put this into action, the data fabric requires the following three solution components for processing metadata:
- Collect
- Enrich
- Use
The diagram below shows more details about each component and how they interact with each other.
In the next article we will talk about the role of each component, the requirements each must satisfy and why knowledge graphs are so effective in meeting those requirements.






